Overview of Statistics used with Experimental Research
I Background
Before we go into the details about how statistics are used in experimental research, there is some background information we need to go over very quickly.
A Types of Variables Typically Used
When doing experimental research, there are two types of variables.
Variables that are manipulated by the researcher and the variables along which people are assumed to have changed.
1. Independent variables - those that are manipulated by the researcher.
Typically these variables are nominal or ordinal in nature.
For example:
Researchers looking at whether or not writing comments on your exams will improve your performance next time around.
Example:*
| Variable: | Comments |
| Levels: | None, A few, Moderate, A lot |
In this case, our independent variable is comments, which is ordinal in nature.
2. Dependent variables - those that are thought to be influenced by changes in manipulated or independent variable.
Typically these variables are interval in nature.
For example:
Variable: Performance on next exam
Levels: 0 to 100.
However, not all dependent variables are interval in nature. Sometimes they are nominal or ordinal. But it is more likely that the variables will be interval.
So, the statistical tests we are going to cover focus specifically on variables that are interval in nature.
There are other statistical tests that can be used when the dependent variable is nominal or ordinal, but we simply don't have time to cover them.
B Symbols Used
There are some symbols that are commonly used when doing statistical tests which you should be familiar with.
Symbols for the Mean
| X | average of a sample |
| m | average of the population (nu) |
Symbols for the Standard Deviation
| SD | standard deviation of a sample |
| s | standard deviation of the population (sigma) |
C Goal
The goal of the statistical tests we are going to cover, is very straightforward. We simply want to determine if the differences noticed between the experimental and control group are due to chance or the manipulation of the independent variable.
Do the differences cross the line. Beyond a reasonable doubt.
In other words, if at the end of an experiment, we notice a change between the control and experimental groups, we use statistics to figure out how likely it was that these differences happened.
For example, in class we did an experiment, where you rated a person's suitability for a job. Half of you were told the person was female the other half were told he was male.
In this example, we noticed that there was a difference between the two groups in terms of how suitable you thought Chris (male or female) was for the job.
You rated Chris on the following scale.*
Very unsuitable for the job |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
very suitable for the job |
People who thought Chris was female: X = 4.5
People who thought Chris was male: X = 3.5
Obviously there is a difference between these two groups. That is, people who thought that Chris was female rated her as being more suitable for the job than people who thought Chris was a male.
However, we need to know if these differences are due to chance, or are they do due the fact that people discriminated against Chris because of his/her sex.
Just by looking at the differences we can't determine if these differences are due to chance or due to discrimination. We have to rely on statistics to determine what happened.
D Tests of Statistical Significance
Basically, the types of statistics being used are called tests of statistical significance. What these tests do, is give us a way of determining whether the difference between groups is due to chance, or is it a significant difference.
Significant difference means that the difference between groups is probably not due to chance. Crosses the line, beyond a reasonable doubt.
So, what we are going to cover is tests of statistical significance that are used to determine whether or not the difference between two groups is due to chance or the manipulation of the independent variable.
The process of determining whether or not two groups are different from each other is called hypothesis testing.
II Overview of Hypothesis Testing
Determining whether or not the differences between groups is significant or due to chance.
When trying to decide whether the differences between two groups are due to chance or due to the manipulation of the independent variable, we are engaged in what is called hypothesis testing.
A Types of hypotheses.
There are several different types of hypothesis, we need to go over in order to understand how statistics are used to determine if differences between groups are real.
Let's use our Chris example as we go through this.
1. Null Hypothesis (Ho)
States that whatever differences we get - they are simply due to chance.
That is, the null hypothesis, says that the two groups represent the same population.
In other words, the two groups are really coming from the same place - they are equal to each other. The differences between the two groups are simply due to chance. They are not real differences.
Null hypothesis are written has follows
Ho: µ1 = µ2
This is a null hypothesis. It simply states that mean of one population is equal to the mean of the other population. That is, the two populations are the same.
In our example, we would write the Null hypothesis like this:
Ho: µChrisMale = µChrisFemale
Simply states that the groups are equal to each other. Differences are due to chance.
The null hypothesis, is the one that is actually being tested. We either "reject" the null hypothesis or we "accept" it.
When we "accept" the null hypothesis, we say that the groups are not different from each other. Differences between groups are simply due to chance.
If we "reject" the null hypothesis, then we have decided that the groups probably aren't equal to each other.
We test the null hypothesis, because statistics allow us to be relatively certain about whether groups are equal to each other, but we can't directly test whether two groups are different from each other.
In other words, we can reasonably rule out that the groups are equal to each other. If we can reasonably rule out that the groups are equal, then we assume that they are different.
No way to directly prove that two groups are different from each other, we can only reasonably rule out that they are similar to each other.
2. Research Hypothesis (H or Ha)
If we reject the null hypothesis, when we have gained support for the research hypothesis.
The research hypothesis or the "alternative hypothesis" is the logical opposite of the null hypothesis.
So, if our null hypothesis says that the groups are equal to each other, then the research hypothesis states that the differences between groups are probably real. That is, the differences between the groups are probably not due to chance.
Ha: µ1 ¹ µ2
If we reject the null hypothesis, then we assume that the groups are different, but we can't prove it.
In the example above our research hypothesis would look like.
Ha: µChrisMale ¹ µChrisFemale
In short, we are saying that the two groups are different from each other. We can't prove this, but we can be reasonably certain that they are not similar to each other.
We will see how this works in a minute. But first, there is one more thing you need to know about hypothesis testing.
B Directionality
Hypothesis can be phrased two different ways.
1. Non-directional hypothesis or Two-tailed hypothesis
Simply means that research hypothesis assumes that the groups are different from each other. The null hypothesis assumes they are similar.
In other words, just assume that the groups are either similar or different, without making a prediction about how they might be different from each other.
Example of non-direction hypothesis:
Ho: µChrisMale = µChrisFemale
Ha: µChrisMale ¹ µChrisFemale
2. Directional hypothesis or One-tailed hypothesis
However, it is also possible that we have a more specific idea about the differences between the two groups. In other words, sometimes our research hypothesis make specific claims about one group not only being different, but being different in a specific way.
That is, we have an specific idea about how two groups will differ from each other.
Let's go back to our example. When I had you fill out the questionnaire about Chris, not only did I have an idea that you'd probably fill them out differently, but let's say that I thought that you would rate the female Chris as being more suitable for the job than the male Chris.
In other words, I not only thought that there would be a difference between the two groups, but I thought you would rate the female Chris higher than the male Chris.
Thus, in this instance, I would have a directional hypothesis.
So, my research hypothesis would actually be:
Ha: µChrisMale < µChrisFemale
Not only different, but different in specific direction.
Null hypothesis has to be the logical opposite of the research hypothesis. So,
Ho: µChrisMale ³ µChrisFemale
This is the actual hypothesis that we test. If we can reasonably rule out the Male Chris received ratings that were higher or equal to the Female Chris than we can assume that Male Chris had lower ratings than the Female Chris.
C Steps Involved
1. State research hypothesis. What you think will happen. Groups will be different (non-directional) or groups will be different in a specific direction (directional).
2. State the null hypothesis. The null hypothesis is the logical opposite of the research hypothesis. It assumes that groups are equal or the differences noticed are simply due to chance.
3. Test whether the null hypothesis is true.
Try to determine if the groups are equal to each other.
If it seems likely that the groups are equal to each other then "accept" the null hypothesis and assume that the groups are NOT different from each other.
If it seems very unlikely that the groups are equal to each other then "reject" the null hypothesis and assume that the groups are different from each other.
How does this actually work?
III Logic Underlying Hypothesis Testing (Tests of statistical significance)
Remember the goal is to test whether two groups are equal to each other.
Well, when doing research it is very unlikely that two groups are going to get exactly the same score.
So, we have to come up with some way of testing whether or not two groups are equal to each other
However, the way we do this is based upon probability theory.
How we determine if differences are beyond a reasonable doubt.
A Based upon Probably Theory
We use probably theory to help us decide if two groups are equal to each other.
1. We determine what the probability is that two groups are equal to each other. That is, what are odds that two groups represent the same population.
2. If the probability or odds that the two groups are the same is low, then we reject the null hypothesis.
It is probably not very likely that these two groups represent the same population.
B Probability is calculated using Distributions of Differences
Remember when we were talking about distributions.
Distributions are simply a way of rank ordering scores
Well, there are also different types of distributions that we can create.
Review of types of distributions.
1. Sample distribution
Simply the scores of a given sample.
2. Population distribution
Simply the scores of the entire population.
3. Sampling distribution
Remember that a sampling distribution was simply taking out all possible samples, calculating the average for each sample, and plotting all of the possible average sample means.
Well, we can do something very similar when trying to determine if the two samples above came from the same population.
4. Distribution of Differences
A distribution of differences is used when trying to decide if two groups come from the same population or not.
A distribution of differences is very straight forward.
Like a sampling distribution, we pull out all possible combinations of samples from the population.
However, this time, instead of drawing one sample at a time, I take two samples at a time.
So, I grab two samples at random from my population.
I calculate a mean for each sample. And then I take the difference between these two means.
That is, I grab two samples, calculate their average. And subtract the difference between these two samples. Put them back in my population and do the same thing again.
If I kept repeating this process, until all possible combinations of samples had been drawn and the distance between all possible combinations had been recorded. Well, I could plot these differences between all possible pairs of sample means.
That is, I could calculate the difference
between all possible samples, and plot them.
This is called a distribution of differences.
This type of distribution is unique in several ways.
1. It is a normal distribution
2. The mean of this distribution is always zero (m diff = 0).
3. Moreover, we can calculate the standard deviation of this distribution.
It's called a Standard Error of the difference (s diff).
4. This distribution is very important, because it is used to determine if two different groups are likely to come from the same population.
Let's go back to our example we did in class.
Now, let's determine whether or not the differences in your reactions to Chris were due to chance or were you reacting his/her sex.
So, let's start by listing our hypothesis.
Ho: µMaleChris = µFemaleChris
Ha: µ MaleChris ¹ µFemaleChris
Next, let's create a distribution of differences.
I know the mean of this distribution is zero (m diff = 0).
I can also calculate the standard deviation of this distribution (Note: this step is beyond what you need to know for this course).
In this case the Standard Error of the difference is (s diff = .50 ).
Well, let's assume that you all came from the same population to begin with -- which you did.
Since you came from the same population and were doing the exact same task, your scores should be similar to each other, within some degree of error.
However, if your scores are different from each other, then the difference must be due to the fact that you reacted differently to Chris in terms of his/her sex.
Well, we know that your scores were not the same.
X MaleChris = 3.5 vs. X FemaleChris = 4.5
Now, the question is. Is the difference between these two groups too great to considered just chance?
That is, at what point do we say that the difference between these two sample means is so great that they just can't be from the same population.
In other words, when do we feel that it is appropriate to reject the Null Hypothesis.
Well, first let's calculate the odds or probability of getting a difference like we did.
This is very easy to do.
Remember z-scores. You could calculate a z-score to see how you did on the first exam.
Well, now we can calculate a z-score to determine how likely it is to get this size of difference between the two groups.
How do we do that?
We take the difference between the two groups and calculate a z-score for this difference.
So, the difference between the two groups is: (3.5-4.5 = -1.0).
I can compare this difference with all of the possible differences that exist..
In other words, just like you could compare you exam score with everyone else's exam score, we can now compare this difference with all other possible differences.
So, let's calculate a z-score for difference we obtained.
z = (difference obtained - mean difference)/ standard deviation of differences
or
z = (-1.0 - 0)/0.5
z = -2
So, the z-score representing the difference between these two groups is -2
What does that mean?
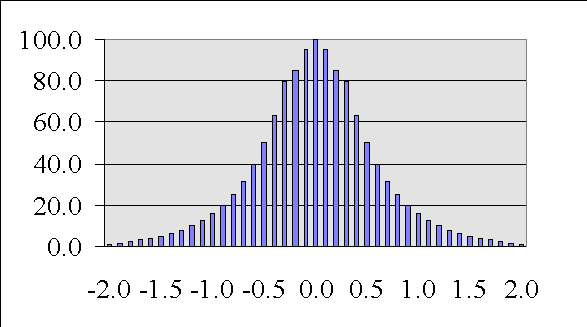
Remember the 68-95-99 rule.
Let's go back to our distribution and find out.
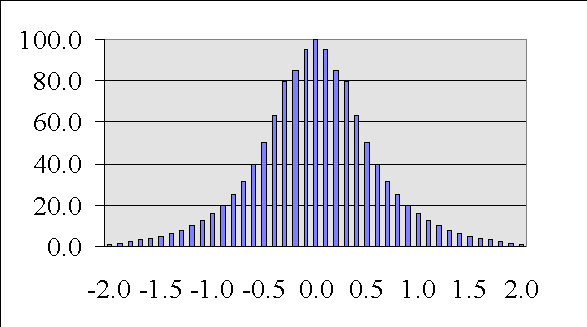
Well, if it my z-score was lower than -3 or higher than +3?
What are the odds of that happening?
Less than 1 time out of a hundred if just drawing samples at random -- (p. < .01).
What if my z-score was lower than -2 or higher than +2.
Less than 5 times out of a hundred if just drawing samples at random -- (p < .05)
What if my z-score was lower than -1 or higher than +1
Less than 32 times out of a hundred if just drawing samples at random - (p < .32).
Now, we must decide if we should reject the null hypothesis. That is, we need to decide if the difference we obtained is due to chance or due to something else.
In social science research it is better to be conservative when deciding that groups are different from each other.
So, typically in the social sciences, we reject the null hypothesis only when the probably or likelihood of obtaining a difference between two groups is low.
We can never be certain that differences are real -- its always a possibility that two samples drawn at random will have extremely different scores, it just isn't very likely. Instead when the odds of a difference occurring is not very likely, we simply assume that the differences are real, and probably not due to chance.
The probability level where social scientists feel comfortable rejecting the null hypothesis is called the significance level.
Typically, social scientists only reject the null hypothesis when the probability level is very low (p. < .05 or smaller).
This is beyond a reasonable doubt. How line is drawn in social science research.
By setting the probability level at (p. < .05) we are 95% sure that the difference is real and not due to chance. We can never be 100% certain.
So, in our example, we would reject the null hypothesis. That is, we are comfortable ruling out the possibility that the differences noted are due to chance (our z score was unusual - only happens five times out of a hundred - the difference between the two groups was very uncommonly). So, we assume that the groups are not equal.
In other words, we would say that people were influenced by Chris's sex when making their evaluations.
When we reject the null at a given significance level we say that the differences between the means or groups is statistically significant.
C Basic Principles Behind Determining if Differences are Significant
1. Find out what the difference between two means or groups is.
2. Determine what the chance or probability is of getting such a difference between two groups.
3. If chance or probability is very low (less than 5% chance - p <. 05) then reject the idea that the groups are equal.
4. Assume that the groups are different. However, you can never be absolutely certain.