- Programs, function calls, stack frames
- Threads and Coroutines
- System Calls
- Interrupts
- Input/Output - Device Drivers
- Linking and Loading
- Booting
| |
(Top of call stack) |
| esp-> |
Local variables
alignment padding
etc. |
| ebp-> |
saved caller's ebp |
|
caller's ret addr |
|
1st parameter |
|
2nd parameter |
|
Rest of caller's stack
frame |
A process is represented by a data structure (i.e., a struct or class)- the
process control block (PCB).
A thread in a process is also represented by another data
structure (i.e., a struct or class) - thread control block (TCB).
A process will have have one or more threads. The PCB may have
a pointer to a list of thread control blocks.
The context of a thread is represented by its
- stack
- register state
- process memory
- open files
- ...
The TCB will need to provide access to all components of the
thread context.
In implementing threads, it will be necessary to transfer
control from one thread to another.
CurrentThread is global pointer to thread control block for
executing thread and executes switch below to give
control to another thread pointed to by next_thread.
void switch(thread_t *next_thread)
{
CurrentThread->SP = SP;
CurrentThread = next_thread;
SP = CurrentThread->SP;
return;
}
It may be desirable for an executing thread to give up the
processor to allow another thread to execute.
It might do this by calling a function:
thread_yield(). Another thread executes and may itself call
thread_yield() causing the first thread to execute again returning
from its call to thread_yield().
The threads are not calling each other, as they are mostly
independently executing. But this transfer of control is known
as coroutine execution.
Which other thread executes when thread_yield() is called?
How is control (i.e. the processor) transferred to the other
thread?
A simple model of system call implementation on the IA32
architecture:
The operating system has a table consisting of exception
handlers (and interrupt handlers)
Each entry consists of a
(1) handler function address
and
(2) a set of flags (as an int)
Each system call has a corresponding system call
number. For example suppose getpid() has system call number
32.
The library routine for getpid() that is linked into a user
program has code like this:
move $32,%eax ; assume 32 is the number for getpid() - no parameters
int $0x80 ; invoke trap instruction
The trap instruction saves the call user's context (registers
including the flags register, %esp, %eip...) AND loads the %eip
and flags register from the entry in the exception table
corresponding to 0x80 AND switches to the kernel stack for this
user.
Note that the processor will be in kernel mode
because of the new flags register value and will be executing
kernel code because of the %eip register value.
The handler for entry 0x80 starts executing in kernel mode.
This handler is for system calls. It just checks %eax and then
indexes into another table (using the value 32 in %eax) to
determine what kernel function is being called - do_getpid() in
this case and calls this function indirectly using the table entry.
The kernel is then executing do_getpid() in the context of the current
thread (and process). A global pointer references the currently
executing current thread. So it can look up the information (pid
in this case) and arrange to return that value.
Returning is a bit different than returning from an oridnary
call as the registers need to be reloaded with the user's saved
registers to restore the user to the user stack and frame. But
also the user's flag register value must be reloaded to return to
user mode.
Interrupts use the same exception handler table.
The same mode switch occurs when an interrupt occurs. However,
instead of being caused by the trap instrucution, the interrupt is
signal is sent by an external device to the processor (INTR line
into the processor). The hardware processor then saves the
currently executing thread's context in its TCB, acknowledges the
interrupt and receives an integer value indicating which handler
to use. This integer is then used in the same way as the 0x80
argument to lookup the handler and begin its execution.
The simple model describe in the text:
- PIO devices (programmed I/O)
- DMA devices (direct memory access)

Write a byte to the device (e.g. a terminal)
- Store the byte in the write register
- Set GoW in the control register
- Check the RdyW bit in status register until it is set
or
- Store the byte in the write register
- Set GoW and IEW bits in the control register
- Be notified when the write completes (by device interrupt)
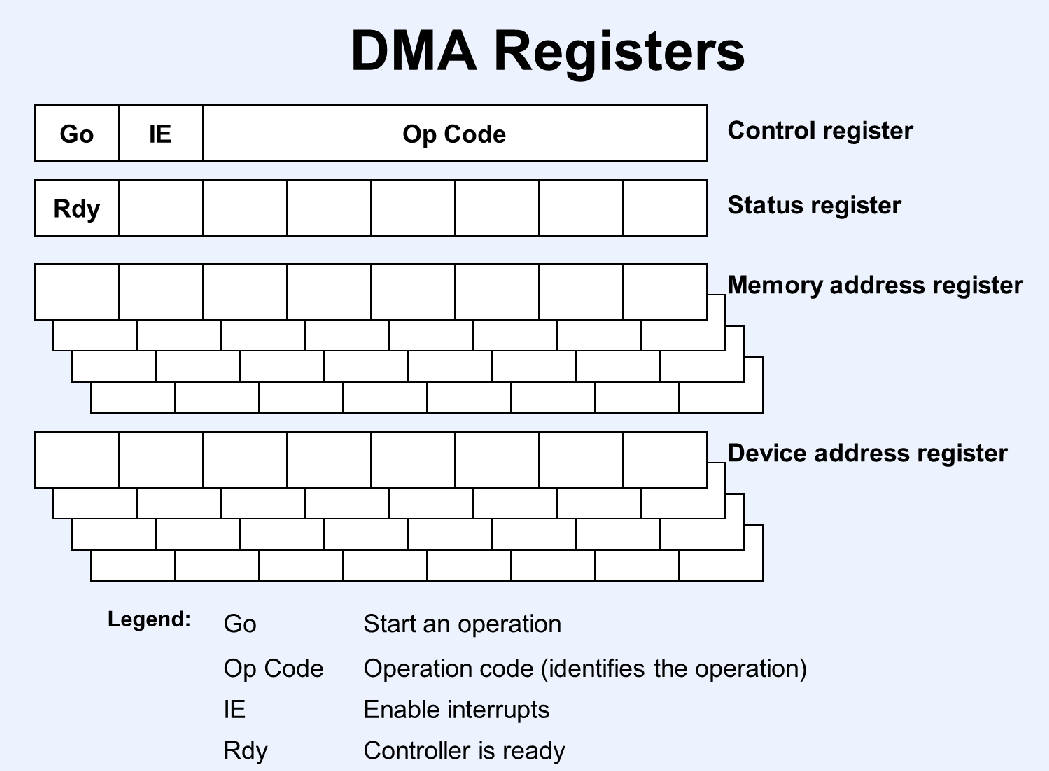
Write contents of a buffer to the disk:
- Set disk address in the device address register
- Set the buffer address in the memory address
register
- Set the op code (write) and the GO and IE bits in the
control register
An executable program will may be built from several source
files and will also include code from library routines.
The C compiler does not know the final address of functions
defined in these other files.
Similarly if a global pointer is initialized with the address
of another global variable, the compiler will not know the final
value of this address to use to initialize the pointer.
The object files created by the compiler must contain
information about which items are missing. The linker/loader then
uses this information to paste the object files together, fix the
missing information, and produce the single executable file.
This describes static linking. The library routines are
included by the linker/loader and are a part of the final
executable file.
Shared libraries (.so files in Linux and .dll files in Windows)
are loaded dynamically at the beginning or perhaps later in
execution. So they are not included directly in the executable
file.
Advantages
Take up less disk space.
Take up less memory space during execution.
Less memory space is used if only one copy of the shared
library code is loaded into memory when multiple processes are using the
library code. The code (but not data) can be shared, right?.
But what about relocation information. Won't it be different
for different processes?
- Does the shared library code have to be loaded into the same
address in each process's address space? (Have the linker/loader
fix all missing addresses assuming the library will always be loaded at the same fixed
address in each processes address space.)
-
Make the relocation unnecessary so that it can be loaded
anywhere in memory without requiring any modification.
This is a bit tricky. Code written this way is called
position-independent-code (PIC).
The technique for producing PIC is to use
indirection. The PIC code refers indirectly to addresses of
routines, etc. to use in the shared library through a table. Each
process can now have different table values with the correct
addresses of where the 1 copy of the shared library is mapped into
that process's address space.
Devices, Terminals, Network Communication
(Read section 4.1.1 - 4.1.2)
A thread may be just created, running, blocked, terminated but
not joined, etc.
Each of these different situations is referred to as the
thread state. The thread control block records the state
and uses it to know what transitions between states are
allowed or appropriate.
Abstractly we might describe the possible thread states as in
chapter 4:
- Runnable
- Running
- Waiting
- Terminated
Thread control is responsible for implementing the
transitions between the states and updating the states as
threads proceed from creation to destruction.
Creating and implementing processes requires system calls;
e.g., fork() in Linux. Why?
Similarly, creating and managing threads would seem to require
system calls.
This would be the one-level model for implementing
threads.
All data structures (Thread Control Blocks) would be in the kernel
image and functions to manage threads would all be kernel code and
would require system calls by user programs.
All these operations would occur in the kernel:
- creation
- termination
- synchronization
- scheduling
Overhead of pthread_mutex_lock(&m) if m is not
locked. Should be very fast and return immediately.
Windows has mutex objects but it also has additional methods
that are also functionally equivalent to pthread's mutexex:
- EnterCriticalSection
- LeaveCriticalSection
Windows essentially uses the one-level model, BUT the
EnterCriticalSection and LeaveCriticalSection methods are
implemented (at least partially) in user level library.
Claim: Using EnterCriticalSection/LeaveCriticalSection is 20
times faster than using Windows mutexes when no waiting is
necessary.
Note: If the critical section is locked, EnterCriticalSection
must make a system call to block the calling thread.
User level library code provides a substantial part of the
thread implementation.
However, the operating system views a multithreaded user
program (using this user library) as being a single threaded
process and schedules the process.
The user library must provide its own scheduler to schedule the
multiple threads within this process.
Advantage: Since the thread library schedules and synchronizes the
multiple threads within the process, the overhead of system calls
is avoided.
Disadvantage: If some thread in the process makes a system call
(not one of the thread library calls) and blocks, then none of
other threads will execute even if they are "runnable".
This model is referred to as having a single "kernel"
thread. Presumably this just means that the operating system views
the process as being a single threaded process and the kernel only
keeps track of scheduling the process.
What does this mean?
In this model we still have a user level thread library but
the operating system now views a user process as potentially
multithreaded. So the operating system may now schedules multiple
threads that area all part of one process. However, the
correspondence is not necessarily one-to-one. For example, more
library user level threads may be created than the kernel
schedules. E.g., a user program uses the user level library to
create 6 threads. The user level library makes system calls and
asks the kernel for 3 threads (scheduled by the kernel).
The user library then does its own scheduling of the 6 user
level threads using the 3 threads known to the kernel. If one of
the 6 threads makes a system call (not a thread library call) and
blocks, then kernel changes the state of the thread to
blocked. But that leaves 2 threads the kernel may still
schedule. So the other 5 threads in the user process may still
have a chance to execute.
Solaris used a version of this model (now changed).
This library manages threads in the process that uses the
uthread functions, including scheduling and
synchronization. However, only one thread in the process executes
at a time and scheduling is non-preemptive!
So this is the 2-level model but with a single "kernel"
thread.
A running user uthread can
yield. This causes the uthread scheduler to select another thread
to execute. Scheduling is based on uthread priority. uthread
condition variables are to be implemented. Unlike pthreads, wait
on a uthread condition variable does not return
spontaneously. This can make some code simpler (such as writing
code for a barrier).
These are mostly defined in file uthread.h.
-
The uthread_t type (aka a thread control block)
typedef struct uthread {
list_link_t ut_link; /* link on waitqueue / scheduler */
uthread_ctx_t ut_ctx; /* context */
char *ut_stack; /* user stack */
uthread_id_t ut_id; /* thread's id */
uthread_state_t ut_state; /* thread state */
int ut_prio; /* thread's priority */
int ut_errno; /* thread's errno */
int ut_has_exited; /* thread exited? */
int ut_exit; /* thread's exit value */
int ut_detached; /* thread is detached? */
struct uthread *ut_waiter; /* thread waiting to join with me */
} uthread_t;
- list_link_t is just 2 pointers: prev and next. Used to
insert the uthread_t on scheduling lists, wait lists.
uthread_state_t is a enum type that holds the current
state of each thread.
typedef enum
{
UT_NO_STATE, /* invalid thread state */
UT_ON_CPU, /* thread is running */
UT_RUNNABLE, /* thread is runnable */
UT_WAIT, /* thread is blocked */
UT_ZOMBIE, /* zombie threads eat your brains! */
UT_NUM_THREAD_STATES
} uthread_state_t;
The thread library maintains a global pointer to the currently executing thread in the process.
uthread_t *ut_curthr;
The uthread_init() function must be called (once) by a
program that uses the uthread library to
initialize the uthread global data structures and to convert
the initial thread of the process to a uthread.
This function should initialize the global uthreads
array. Each entry should be initialized to indicate not yet in
use:
- ut_state should be set to UT_NO_STATE
- ut_id should be initialized; e.g, uthreads[k].ut_id
can be set to k.
- ut_stack set to NULL
- ut_prio is used as the index into an array of queues. To
initialize this as unused, it could be set to -1.
- ut_errno can be set to 0 (no error)
- ut_waiter pointer to thread that has called uthread_join
for this thread. Set to NULL.
/* these should go last and in this order */
uthread_sched_init();
reaper_init();
create_first_thr();
This should initialize the multilevel scheduling queues. You
need to implement it.
The array of is global in uthread_sched.c:
utqueue_t runq_table[UTH_MAXPRIO + 1];
where UTQ_MAXPRIO is defined as 7.
The utqueue_t type is a doubly linked list. A function to
initialize it (as empty) is utqueue_init in the file
uthread_queue.c
This function and the reaper() function itself are
provided.
In implementing the user level thread library, you are
responsible for cleaning up a thread: deallocating its stack and
so on.
When does this occur? What thread does it? (It has to be a user
level thread; it isn't handled by the kernel.)
This is were the reaper() function plays a role. A reaper
thread (with reaper() as its start function) is to clean up
detached threads.
Test programs or any program that will use the uthread library
will begin as a single threaded Linux process and not yet a
uthread.
So that program needs to be "transformed" into an initial
uthread.
This function is provided and will become the first uthread for
this process. Any uthread in the program can then call
uthread_create(...) to create additional uthreads.
Check for the same errors that pthread_create does. If an error
occurs set errno to the symbolic integer and return -1.
- Check pointer to caller's uthread_id_t is not
NULL. (E.g. use assert()
- Check priority is valid. If not set errno to EINVAL and
return -1.
- The uthread_alloc function (you implement) should be called
to get an id for the uthread to be created. If no free entry in
the uthreads table, set errno to EAGAIN and return -1.
Note that errno is redefined so that it is thread
specific. When a thread is the currently executing thread,
errno is the member in that thread's uthreads entry.
Create a stack for the new thread and set this member in
this thread's uthreads table entry. You can use the
alloc_stack() function. It allocates a stack of size
UTH_STACK_SIZE (64k bytes). errno = EAGAIN if alloc_stack()
fails (returns NULL).
- Create the context for this thread and set its ut_ctx entry
in the uthreads table. Use the uthread_makecontext
function.
This entry in the thread control block (i.e., the uthread_t
structure)
What is this?
It is a data structure to hold:
- The thread's signal mask
- Its execution stack
- Machine register values
Linux provides functions for initializing and swapping this
context information:
- int getcontext(ucontext_t *ucp)
- int setcontext(const ucontext_t *ucp)
- int swapcontext(ucontext_t *olducp, ucontext_t *newucp)
- void makecontext(ucontext_t *ucp, void *f(), int argc, ...)
void makecontext(ucontext_t *ucp, void *f(), int argc, ...)
(See problem 3 in chapter 3?)
This creates a context and stores it in the struct pointed to
by ucp. In particular, it sets up the stack so that when some
thread switches to this context (how? by switching to the stack
and returning) the function f will be called with the specified
arguments on its stack.
A thread can switch to another context by calling swapcontext
or setcontext.
int getcontext(ucontext_t *ucp);
This stores the context for the calling thread in the structure
pointed to by ucp.
The uthreads project runs on Linux. To get the initial code for
the uthreads project use wget from Linux:
wget http://condor.depaul.edu/glancast/443class/hw/uthreads.tar
Then extract uthreads.tar in a directory of your choosing.
Type:
make nyi
to see the functions not yet implemented.