- null
- non-null and marked with true -- active
- non-null and marked with false -- deleted or inactive
- a null slot -- put the element as active there; or
- a slot that has the same value (X) and is active is encountered -- duplicate is found, no insertion
Example:
Assume the type of X is int, M is 10, and the hash function returns X % M.
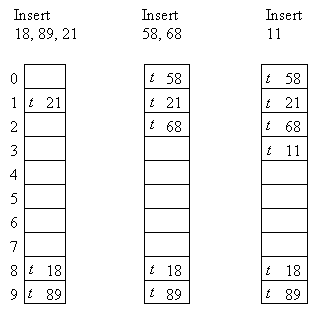
- the element to search which is marked active is found (success)
- a null slot is encountered (fail)
- Can NOT mark the slot for X empty -- messes up the find operation
- Do lazy deletion by marking the item deleted.
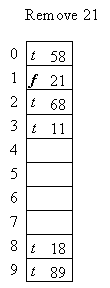
-
With this scheme, no item is physically removed until array is rehashed.
-
NOTE: Any non-null slot that is marked deleted can NOT be re-used by insertion (except for the case when the same item is re-inserted) -- WHY??
Primary Clustering problem
|
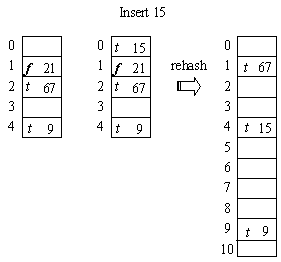
- Usually to extend the size of the table, to the next prime from 2 * current_table_size.
- Performed when the load factor becomes more than a fixed value (e.g. 0.8).
- Usually applied as the LAST STEP IN INSERTION, to keep the table under the specified load factor.
- Distribute existing active elements to the new table by applying
% by the new table size, from table[0] to table[M-1].
e.g. Initial table M = 5, maximum load factor = 0.75
Let λ be the load factor.
| Successful Search: | 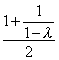 |
| Unsuccessful Search: | 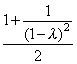 |
| Insert: | 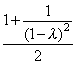 , same as
unsuccessful search , same as
unsuccessful search |
Some examples:

