If R is a relation on a set A, R is of course not necessarily transitive.
At the other extreme, R is contained in A x A, and A x A is a transitive relation on A.
But A x A as a relation on A that contains R is too big to be of much use since by definition, (x,y) is in this relation for every x and y in A.
Instead what is often useful is the smallest transitive relation that contains R.
If R and S are relations on a set A, the product of R and S, denoted by RS is defined by
RS = { (x,y) | there is some z in A such that (x,z) is in R and (z,y) is int S }
Lemma (Associativity): If R, S, and T are relations on a set A, then (RS)T = R(ST).
Proof: (x,y) in (RS)T => there is a w in A such that (x,u) is in RS and (u,y) is in T. But (x,u) in RS => there is a v in A such that (x,v) is in R and (v,u) is in S.
Now, (v,u) in S and (u,y) in T => (v,y) is in (ST).
Since (x,v) is in R and (v,y) is in (ST), (x,y) is in R(ST).
If R is a relation on a set A, and k is any integer >= 0, define, a relation Rk inductively by:
R0 = {(x,x) | x is in A }
R1 = R
Rk = Rk-1R for k > 1
Note that
R2 = R1R = RR R3 = R2R = (RR)R But by the associativity lemma, (RR)R = R(RR).
The associativity lemma means it doesn't matter what order you compute the products when computing Rk. So, for instance, we can unambigously write
R3 = RRR since (RR)R = R(RR)
For any relation R on a set A with n elements, define relations R+ and R* on A by
R+ = R1 ∪ R2 ∪ ... ∪ Rn-1 ∪ ... R* = R0 ∪ R1 ∪ R2 ∪ ... ∪ Rn-1 ∪ ...
R+ is called the transitive closure of R
R* is called the transitive, reflexive closure of R
Lemma: If R is a relation on a finite set A that has n elements, and for some integer m > 0, (x,y) is in Rm, then (x,y) is in Rk for some k such that 1 <= k < n
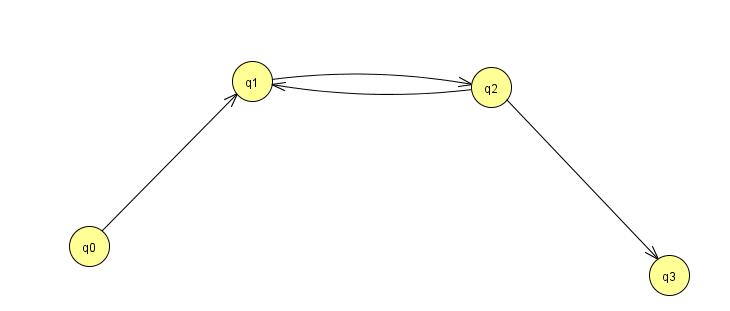
Example: R is the relation on the set A = {q0,q1,q2,q3} whose graph is shown below. That is, (qi, qj) is in R if there is a directed edge from qi to qj.
Note: In this example, 1. n = 4 2. (q0, q3) is in R5 (so m = 5): q0, q1, q2, q1, q2, q3 is a path of length 5 in the graph of R. (qi-1, qi) is in R for i = 1,2,3,4,5 But q1 is the first element of A that is repeated later in this path so we can remove the elements between the first occurrence of q1 and the last occurrence: 3. q0, q1,q2, q1,q2, q3 is a path of length 3 in the graph of R. So (q0, q3) is also in R3 (So k = 3 < n = 4).
Lemma: If R is a relation on a finite set A that has n elements, and for some integer m > 0, (x,y) is in Rm, then (x,y) is in Rk for some k such that 1 <= k <= n
Proof: The proof is by contradiction. Let k be the smallest integer >= 1 such that (x,y) is in Rk. Then we know k <= m. Assume k > n.
Since (x,y) is in Rk, there is a sequence u0 = x, u1, u2, ..., uk = y of k+1 elements of A such that (ui-1, ui) is in R for each i = 1, 2, ..., k.
By assumption k > n and since there are only n elements in A , there must be a repetition in the first k elements u0, u1, ..., uk-1 (without considering uk).
Let r be the subscript of the first element among u0, u1, ..., uk-1 that is repeated later in the same sequence.
Let s be the subscript of the last occurrence of this same element in u0, u1, ..., uk-1.
Then, ur = us, 0 <= r < s <= k-1
x = u0, ... ur, ur+1, ... us = ur, us+1, ... uk-1, uk = ySince (ui-1, ui) is in R for 1 <= i <= k, this says (x,ur) = (u0, ur) is in Rr and (ur, y) = (us, y) = (us, uk) is in Rk - s.
And so (x,y) is in RrRk - s = Rk - (s - r).
But
1 <= k - (s - r) < k (why?)which contradicts the assumption that k was the smallest integer >= 1 such that (x,y) is in Rk.
If R is a relation on a finite set A with n elements, then
R+ = R1 ∪ R2 ∪ ... ∪ Rn R* = R0 ∪ R1 ∪ R2 ∪ ... ∪ Rn
Proof: Follows from the previous lemma.
Proposition: If R is a relation on A, then R+ is a transitive relation on A and is the smallest transitive relation that contains R.
Proof: First, show that R+ is transitive.
(x,y) in R+ and (y,z) in R+ => (x,y) is in Ri and (y,z) is in Rj for some i and j. But this says that (x,z) is in RiRj = Ri+j which is contained in R+.
A similar argument shows R* is transitive.
Let G be the following context-free grammar
S -> E $
E -> E '+' T | T
T -> T '*' F | F
F -> 'id' | '(' E ')'
Define a relation R on {S,E,T,F, '+', '*', 'id', '(', ')' }
By R =
{
(S,E)
(E,E)
(E,T)
(T,T)
(T,F)
(F, 'id')
(F, '(')
}
Is R transitive? No.
What is the transitive closure, R+
What is S R+ related to? That is, what are all the values
of w such that (S,w) is in R+
Answer: (S,E), (S,T), (S,F), (S, 'id'), (S, '(')
Let G = (V, T, S, P) be a context-free grammar.
Define a relation R on (V ∪ T)* by
(α, β) is in R if
1. α = uXv for some u, v in (V ∪ T)* and X in V, and
2. β = uwv, and
3. X -> w is a rule in P
Then, L(G), the language of G, is
{ w in T* | (S, w) is in R+ }
Note also that (S, w) is in R+ if and only if
(S, w) is in Ri for some i >= 1.
The following notation will be also be used for the relation R of Example 2
Notation:
For (x,y) in R, write x => y
For (x,y) in Rk, write x =>k y
For (x,y) in R*, write x =>* y
For (x,y) in R+, write x =>+ y
Proposition For any relation R on a set A, R+ and R* are transitive relations on A.
Proof:(x,y) and (y,z) in R+ => there is an integer i >= 1 such that (x,y) is in Ri and also an integer j >= 1 such that (y,z) is in Rj.
So (x,z) is in RiRj = Ri+j where (i+j) >= 2, which implies (x,z) is in R+
The proof for R* is essentially the same, except i and j are only >= 0.
Proposition:For any relation R on a set A, R* is reflexive.
Proof: R* contains R0 = { (x,x) | x is in A}, so R* is reflexive.
Recall the relation R defined for a context-free grammar in Example 2:
Let G = (V, T, S, P) be a context-free grammar. R is the relation on (V ∪ T)* defined by (α, β) is in R, or equivalently, using the alternate notation, α => β if 1. α = uXv for some u, v in (V ∪ T)* and X in V, and 2. β = uwv, and 3. X -> w is a rule in P If S =>+ w and w is in T*, then w is a sentence for the grammar G; w is in the language generated by G. If S =>* w, where w is in (V ∪ T)*, then w is called a sentential form for G.
Let G be the following context-free grammar
S -> E $
E -> E '+' T | T
T -> T '*' F | F
F -> 'id' | '(' E ')'
then
(a) S =>3 T '+' T
(b) S =>+ T '+' T
(c) T '+' T is a sentential form
We can define a restricted version of relation => for context-free grammars for left-most derivatiosn.
For a context-free gramar G=(V,T, S, P),
define RL to be the relation on (V ∪ T)*
by
( α, β) is in RL if
1. α = uXv for some u in T*,
v in (V ∪ T)* and X in V, and
2. β = uwv, and
3. X -> w is a rule in P
Note: The only difference between relation R of Example 2 and
RL is in condition 1. For RL, u must consist of
only terminal symbols so that the X must be the left-most non-terminal
of α.
where t is in T and w is in (V - {S})*
S -> a S B | a B
B -> b
S -> a A | ε
A -> a A | b B
B -> b B | ε
S -> i A | i A B | x
A -> i A | i A B | x
B -> e A
Every context-free grammar can be converted to an equivalent grammar in Greibach normal form. The first step is to convert the grammar to Chomsky normal form!
If a sentence w for a grammar G has length n > 0 and G is in GNF, then any derivation of w must have length n.
Can you describe an algorithm that accepts any context-free grammar G and a string w of terminals and determines whether w is in the language of G? It doesn't have to be efficient, but ε grammar rules cause some problems.
Greibach normal form is useful in showing that any context-free language is the language accepted by some (nondeterinistic) push down automaton. (PDA).
Rules in context-free grammars are not required to meet in the Greibach normal from restrictions.
So to convert a given grammar G to Griebach normal form, we will need a way of replacing grammar rules, but the new grammar must be equivalent to G.
Lemma (Substitution): Suppose a variable B in a grammar G = (V, T, S, P) has productions B -> w1 | w2 | ... | wk. If A is a variable in G that has a production A -> uBv, then let G1 = (V,T,S, P1) be the grammar obtained from G by adding rules A ->uw1v | uw2v | ... | uwkv and deleting rule A -> uBv from the rules for G. Then G1 is equivalent to G.
Proof: L(G) is contained in L(G1).
If S =>* w for w in L(G) and the derivation doesn't use the rule A -> uBv, then the same derivation shows w is in L(G1).
If S =>* w uses the rule A -> uBv, then it must be of the form:
S =>* r1As1 => r1uBvs1 =>* r2uBvs2 => r2uwivs2 =>* w.
The the following is a derivation for w in G1.
S => r1As1 => r1uwivs1 =>* r2uwis2 =>* w
L(G1) is contained in L(G).
Suppose w is in L(G1). If a derivation for w in G1 doesn't use any of the new rules A ->uwiv, then the same derivation shows w is in L(G).
If any of the rules A -> uwiv is used in a derivation in G1 for w, the derivation only has to be modified to use two steps for each such rule to get a derivation in grammar G:
If S =>* ...A... => ...uwiv... =>* w in G1, replace the step ...A...=> ...uwiv... by two steps
...A...=> ...uBv... => ...uwiv...
Eliminating Left Recursion
Lemma (Left Recursion) Suppose a variable A in a grammar G = (V,T,S, P) has left recursive rules
A -> Au1 | Au2 | ... | Aum
and non-left recursive rules
A -> v1 | v2 | ... | vm
Let G1 = (S, V ∪ { B }, T, P1) where B is a new variable not in V and P1 is obtained from P by replacing the rules for A by:
A -> v1B | v2B | ... | vmB |
v1 | v2 | ... | vm, and
introducing new rules for B:
B -> u1B | u2B | ... umB | u1 | u2 | ... | um
Then G1 is equivalent to G.
Proof: In a left-most derivation any use of a sequence of the left-recursive rules A -> Aui must end with one of the non left-recursive rules A -> vj.
The sequence of replacements
A => Aui1 =>
Aui2ui1 => ... =>
Auipuip-1
... ui1=>
vjuipuip-1
... ui1
in G can be replaced in G1 by
A => vjB => vjuipB => vjuipuip-1B => ... => vjuipuip-1 ... ui2B => vjuipuip-1 ... ui2ui1
This shows that L(G) is contained in L(G1).
And conversely, if the rules for B are used to derive a string w in G1, then we can replace the sequence above in reverse to get a derivation for w in G.
Any grammar can be converted to Chomsky normal form. So G is assumed to already be in Chomsky normal form.
Rename the variables of the grammar if necessary as A1, A2, ...Am
After the process below, only rules of this form will remain
for k = 1 to m
{
for j = 1 to k - 1
{
for each Ak -> Aju
{
for all Aj -> v
{
add Ak -> vu
remove Ak -> Aju
}
}
for each Ak -> Aku
{
add rules Bk -> u and Bk -> uBk
remove Ak -> Aku
}
if ( Bk was added ) {
for each Ak -> v where v does not start with Ak
{
Add Ak -> vBk
}
}
}
}
A1 -> A2A3 | x A2 -> A2A3 | x A3 -> A4A5 A4 -> + A5 -> x
Griebach: First Step
The rules for variables A1, A2, ... A5 will be modified one at a time so that when Ak is modified
After the rules for each Ai will be in the correct form, beginning with a terminal followed by 0 or more variables.
The rules for the Bi's will either be in the correct form or be a string of variables beginning with some Ai. Substitute all the right side choices for Ai in this rule for Bi.
A1 -> A2A3 | x A2 -> A2A3 | x A3 -> A4A5 A4 -> + A5 -> x
The rule for A1 is not recursive and no index is < 1. So nothing to do for A1.
A2 does not require substitution since there is no rule of the form A2 -> A1..., but A2 does have a recursive rule. So use the left-recursion elimination to get:
A1 -> A2A3 | x A2 -> xB2 | x // Replaced A2 -> A2A3 | x B2 -> A3B2 | A3 // A3 -> A4A5 A4 -> + A5 -> x
Rules for A3, A4, and A5 require no replacements.
A1 -> A2A3 | x A2 -> xB2 | x B2 -> A3B2 | A3 A3 -> A4A5 A4 -> + A5 -> x
A4 and A5 rules are in Greibach normal form.
For A3, replace leading A4 on the right side.
A3 -> +A5.
Skip B2.
A2 rules are in Greibach normal form.
For A1, replace leading A2 on right side with all choices for A2:
A1 -> xB2A3 | xA3 | x
Result:
A1 -> xB2A3 | xA3 | x A2 -> xB2 | x B2 -> A3B2 | A3 A3 -> +A5 A4 -> + A5 -> x
Finally replace leading A3 in rules for B2
B2 -> +A5B2 | +A5
A1 -> xB2A3 | xA3 | x A2 -> xB2 | x B2 -> +A5B2 | +A5 A3 -> +A5 A4 -> + A5 -> x
The string x + x + x has length 5.
Give a derivation for x + x + x for the Greibach normal form grammar. How many derivation steps?
A1 -> xB2A3 | xA3 | x A2 -> xB2 | x B2 -> +A5B2 | +A5 A3 -> +A5 A4 -> + A5 -> x
For a GNF grammar, every sentential form will be uv where u is a string of 0 or more terminals and v is a string of 0 or more variables!
For a PDA (Q, ∑, Γ, δ, q0, F), we will consider triples (q, w, v) where q is in Q, w is in ∑*, and v is in Γ*. That is, we consider the set A = Q x ∑* x Γ*.
We define a relation R on A by:
Define (q,aw, Xv) is R-related to (p,w,uv) if δ(q,a,X) contains (p, u) Note that a may be ε or an input symbol; that is a is in ∑ε
The language recognized by the PDA can then be defined in terms of the transitive closure of R, R+.
w is recognized by the PDA if (q0, w, ε) is R* related to (p, ε, u) for some final state p. Note that the stack doesn't have to be empty, although the PDA may enforce this by not entering a final state unless the stack is empty.