Backtracking Algorithms
Priority Queue Assignment
Trees
For what kind of problems is a backtracking algorithm feasible? a. Problems whose solutions consist of making a sequence of selections. b. For each selection there are a number of possible candidate choices. c. There is a way of determining if a proposed candidate is acceptable for the next selection given the current selections already made. d. There is a way of determining if a sequence of selections already made is a solution to the problem. Examples: Maze, Knight's tour, generating permutations.
Generate a permutation of S = {1,2,3,4,5}
a. A selection step is to choose an integer from the set S.
Generating a permutation consists of making a sequence of such
selections.
b. For each selection there the possible choices must come from
S = {1,2,3,4,5,6}
c. However, a candidate from S is acceptable for the next selection
only if it has not been selected already.
d. A sequence of selections is a permutation if we have made 6
selections.
1. Although this fits the criteria for using a backtracking approach, we would never have to "back track". 2. Backtracking becomes necessary if the next selection step might be valid with respect to the selections already made, but there is no sequence of additional steps that provide a solution. 3. The point is that at this next selection which is valid with respect to the past selections, we don't have a way of knowing whether there is a sequence of additional steps that will provide a solution. 4. With backtracking, we just keep making additional steps and eventually reach a step where there are no valid next selections. We can't tell the future, we have to suffer through the experience to find that the selection made back several steps ago was the wrong one.
1. When we reach a selection step which has no remaining valid selections, we need to retreat to the previous selection step. This can be done if we have saved all the previous selections. 2. Since we want to retreat to the most recent selection step, saving the previous selections on a stack is appropriate. We just pop the stack (or get the top element without removing it). 3. What information should be saved on the stack?
A fairly general answer might be to save
a. The choice made for that selection.
b. The list of remaining untried next choices (in case this
choice doesn't work out and we have to backtrack).
For the maze or the knight or the 8 queens problem, 1. Each selection choice is a "position" is a (row, column) pair. 2. The remaining choices is then a list of such positions. We are supposed to save both on the stack. How do we represent this in C++?
We could represent a (row, column) position as two separate integer
variables, but we need to treat the pair as a unit.
Create a class
class Position
{
int row;
int col;
public:
Position(int r, int c) : row(r), col(c) {}
int getRow() const { return row; }
int getCol() const { return col; }
};
1. Instances of this class are immutable.
2. How would we declare a stack of Positions and push position (3,4)
on the stack?
How would we declare a stack of Positions and push position (3,4) on the stack? #include <stack> #include "Position.h" stack<Position> s; // Push position (3,4) on the stack s.push( Position(3,4) ); But wait! For backtracking we need to save both the Position choice and also the list of untried positions! 1. How do we represent the list of untried positions in C++? With this revision, we need to save a pair: (a Position, a list of untried positions). 2. How do we declare a stack of these (position, list) pairs and how would we push the position (3,4) and the list of remaining candidate positions from (3,4). This leads to another question: 3. How do we generate the list of candidate positions from a given position?
Before going further, let's try to plan a modest object oriented approach to the solution for the knight's tour problem (but you can also think of the maze problem). Responsibilities (or actions needed) 1. Initialize the Knight's board 2. Print the board with the knight's tour solution 3. Get the list of candidate positions from a given board position 4. Check if a position is a valid board position (on the board and not blocked) 5. Create a Position 6. Get the row and column of a position 7. Find a Knight's path through the board or determine that there is no such path. 8. Mark a position in the board as part of a path. 9. Unmark a position (in case backtrack is necessary). 10. Check if a tour of the entire board has been completed Classes: Responsibilities KnightSolver 1,2,3,4,7,8,9,10 Position 5,6,
KnightSolver data members The KnightSolver class has the responsibility to initialize the board and later, marking a path in the board. So the knight class should have a data member to represent the board. A 2-dimensional array of integers plus the number of rows and columns: int board[8][8]; int rows; int cols; Knight function members Responsibility 1. Initialize the knight What will the user need to pass? (Try to make it easy and convenient to use.) Need to identify knight positions as free, marked, or blocked So we could decide on free: 0 marked: 1, 2, ... consecutive integers for each step in the path. blocked (a wall): ?? Ok, all the non-negative numbers are used, so -1.
KnightSolver Function Members
1. Initialize the Knight's board
KnightSolver(); // Constructor
Initialize all entries of the board to 0
2. Print the board with the knight's tour solution
string toString() const; //
Print the board with the knight's tour
Can be used to overload operator<< for printing
and is more versatile than providing a "print" member.
ostream& operator<<(ostream& os, const KnightSolver& k)
{
os << k.toString();
return os;
}
3. Get the list of candidate positions from a given board position
??return type?? genCandidates(const Position& pos) const;
Return a list of the candidate positions from pos.
4. Check if a position is a valid board position (on the board and not
blocked)
bool valid(const Position& pos) const;
7. Find a Knight's path through the board or determine that there is no such
path. Allow the caller to specify the starting position.
bool solve(const Position& pos);
Will find a path and mark the board with the path if
one exists using backtracking and return true. If no such
path exists, solve should return false.
8. Mark a position in the board as part of a path.
void record(const Position& pos);
Mark the board with the next number in the sequence.
We should add a data member, 'move' to KnightSolver for this
counter. The record method increments the counter and assigns
its value to board[i][j] where i and j are the row and column
values of the position, pos.
9. Unmark a position (in case backtrack is necessary).
void undo(const Position& pos);
The counter, 'move' must be decremented - take back the move.
Also mark board[i][j] to be free, where i and j are again the
row and column values of the position, pos.
10. Check if a tour of the entire board has been completed.
bool done(const Position& pos);
Just check the 'move' counter. Return true if move is the right
thing for a complete tour.
What should the return type be? It can be a list of positions in the order that the solve method will try them. #include <list> using namespace std; ... list<Position> genCandidates(const Position& pos) const;
1. Backtracking needs to save the position and the list of remaining
untried candidates from that position.
2. Using the c++ template 'pair' class with members 'first' and
'second', the type to save could be
pair<Position, list<Position> >
3. Long names like this can be common when using templates. One way to
cut down on the lenght is to use the C language feature (and so also a
C++ feature) that allows us to give an alternative name to a type or
type expression: typedef
Suppose we want to name the type above, PosCandList. Then use this
declaration in the scope where the name is needed; e.g., in the solver
function:
typedef pair<Position, list<Position> > PosCandList;
4. Declaration and use of the stack now can use PosCandList:
stack<PosCandList> s;
...
5. To push a position, pos, and its candidate list on the stack:
s.push( PosCandList(pos, genCandidates(pos)) );
bool solve(const Position& pos)
(Use typedef if desired, declare the stack and any other needed
local variables for the solve function.)
1. Check if pos is a valid starting position. If not, return
false. There is no solution from this starting position.
2. Otherwise, mark this position. (Call record(pos)).
3. Save this position pos and the list of candidate positions from pos
on the stack. These candidate positions have not yet been tried.
Note the invariant that should always be maintained about
the position, list pair at the top of the stack:
a. The position, pos, has already been marked.
b. The list consists of all the possible candidate positions from
pos that have not yet been tried. The genCandidates
function can easily only insert valid positions into its
return list. These untried positions will then be valid for
pos (think about this) So they need not be checked again now
before moving to one of them.
As long as we haven't successfully completed a tour (use a bool
variable, success) and the stack is not empty, the current position
will be the one on top of the stack together with its remaining list
of next positions to try.
Note: If the stack is empty, we have tried all candidates from all
positions and all have failed.
So repeat the following steps as long as success is false and the
stack is not empty.
4. Get the pair on the stack top: Position, pos, and list, cand.
5. If done(pos) returns true, set success = true, else
6. If the list of remaining candidate positions, cand, is not empty,
(a) remove the front position, (b) mark it, (c) push it and the
list of candidates generated from it on the stack, else
7. (There are no remaining candidates from pos, so we have to backup to
the previous position.) So (a) 'undo' this position (call undo which
unmarks the position and decrements the move counter) and (b)
remove this position (and its now empty list) from the stack.
(You could add a counter here to see how many times you have to
backtrack.)
The choice of vector versus list versus some other "container" data structure generally depends on suitability of methods and/or efficiency. In most cases the vector and list have very similar methods. As an example, you are asked to implement a new class, PQueue, and decide whether to use a vector, deque, or a list data member to implement this class.
template <class T>
class PQueue
{
... m; // Either a Vector or a List
void insert(const T& n);
T deleteMin();
bool empty();
unsigned int size();
};
Notes:
1. The insert() method does specify an index or position; that
is, this is not like a normal queue where insertion is at the "end".
2. The deleteMin() method is also not like a normal queue where remove
operations occur at the "front". Instead deleteMin() removes the
smallest element. For this reason, the types that can be instantiated
for the template paramter T must be types for which the comparison
operators, <, etc. are defined.
Cost of operations
N = size()
vector deque list
method member member member
------------------------------------------------
insert O( ?? ) O( ?? ) O( ?? )
deleteMin O( ?? ) O( ?? ) O( ?? )
a. vector
a.1 If insert just adds n to the end, then deleteMin must
search the entire vector to find the smallest element,
insert = O(1) (amortized)
deleteMin = O(N)
a.2 If insert keeps the vector in increasing sorted order at
each insertion, then deleteMin can just remove the first element
without searching. However, removing the first element requires
moving the remaining elements back one index. So,
insert = O(N) (worst case)
deleteMin = O(N)
(Note that O(N) is clearly the worst case for insert; the average
case for an insert is a bit trickier, but is still O(N).)
a.3 If insert keeps the vector in decreasing sorted order at
each insertion, then deleteMin can just remove the last element and
so,
insert = O(N) (worst case)
deleteMin = O(1)
b. deque
b.1 If insert just adds n to the end, then deleteMin must
search the entire vector to find the smallest element,
insert = O(1) (amortized)
deleteMin = O(N)
b.2 If insert keeps the deque in increasing sorted order at
each insertion, then deleteMin can just remove the first element
without searching. However, unlike the vector, removing the first
element requires only constant time for a deque.
insert = O(N) (worst case)
deleteMin = O(1)
b.3 If insert keeps the deque in decreasing sorted order at
each insertion, then deleteMin can just remove the last element and
and just as for a vector,
insert = O(N) (worst case)
deleteMin = O(1)
b. List
b.1 Like a.1,
insert = O(1) (always not just amortized)
deleteMin = O(N)
b.2 The insert method can keep the List in sorted order (it
doesn't matter whether the order is increasing or decreasing). Then
deleteMin() just removes the smallest element from the front (if the
elements are kept in increasing order) or from the end (if the
elements are kept in decreasing order). However, the insert method
must not use the List get(int i) method in locating the index
were to insert n. Instead, it must use a ListIterator.
Using an iterator to locate the place to insert,
list<int>::iterator p = lst.begin();
while( p != lst.end() && n > *p) {
p++;
}
lst.insert(p, n);
insert = O(N)
deleteMin = O(1)
There is no operator[] for list since accessing lst[i] it would take time
proportional to the index i.
Trees can be described mathematically. They can also be described as abstract data types and implemented concretely as types in C++ or another programming language.
Mathematically, a tree is a connected graph with N vertices and N-1 edges, having one vertex denoted as the root.
As an abstract data type, a tree has a set of operations including insertion, deletion operations. Specializations may offer guarantees on the running time of each operation and/or guarantees on the running time of a sequence of M operations.
Vertices and edges are implemented a Node instances and references to Nodes respectively.
For example,
class AbstractBinarySearchTree
{
// Root of the tree:
Node root;
// "Vertices" of the tree are instances
// of Node:
class Node
{
int data;
Node *left;
Node *right;
...
};
// BinarySearchTree methods:
virtual void insert(int n) = 0;
virtual void remove(int n) = 0;
virtual int find(int n) = 0;
virtual int findMax() = 0;
virtual int findMin() = 0;
virtual boolean isEmpty() = 0;
virtual void printTree() = 0;
}
1. An ordered tree is either
a. empty or
b. consists of a root node, r and
c. a sequence of zero or more nonempty trees
T1, T2, ..., Tk.
There is a directed edge from the root node r to the root
node of each of the trees, Ti.
The root node r is the parent of the root node of each
Ti and each of these roots is the child of r.
3. Nodes with no children are leaves.
4. A path from a node p to a node q is a sequence of nodes from
p to q such that each node is the parent of the next node.
5. The length of a path is the number of edges in this path.
6. The depth of a node in a tree is the length of the
a path from the root to the node.
7. The height of node in a tree is the length of longest path
from the node to a leaf.
8. The height of a tree is the height of the root.
The definition of a tree does not restrict how many children a node can have.
XML (and some html) documents have a tree structure. For example a <table> ... </table> tag can be considered the root of a tree. A table can contain rows indicated by the <tr> ... </tr> tag. The <tr> ... </tr> tag can be considered as the child of the table tag. So the children are ordered, but their number can vary for each table.
A node abstract class to handle variable number of children is shown below.
class TreeNode
{
virtual int getData() = 0;
virtual void SetParent(TreeNode *n) = 0;
virtual TreeNode * getParent() = 0;
virtual void AddChild(TreeNode *n, int i) = 0;
virtual TreeNode *getChild(int i) = 0;
virtual int getNumChildren() = 0;
}
Binary trees restrict the number of children to at most 2.
A typical node structure is:
class BinaryNode
{
int data;
BinaryNode *leftChild;
BinaryNode *rightChild;
}
Binary trees can be used to represent binary expressions such as:
(a + b) * c
where each identifier a, b, c is represented as a leaf node and binary operators are non-leaf nodes.
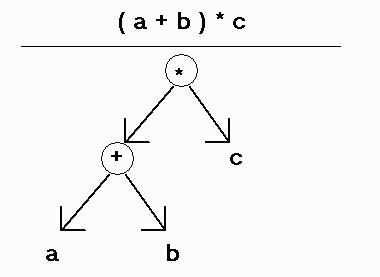
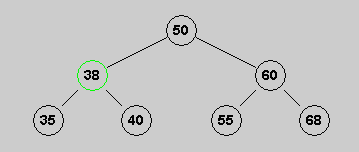
A very useful tree structure is the Binary Search Tree.
A binary search tree is a binary tree with the additional
property that for every node n,
1. All data in the left subtree of n is smaller than the data
in n
and 2. All data in the right subtree of n is larger that the data
in n.
Equality is allowed in 1 and 2 only if duplicates are allowed in the tree.
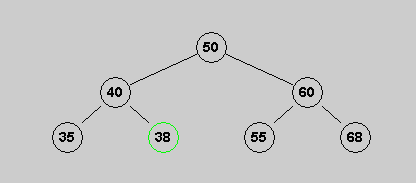
The first tree below is a valid binary search tree; the second, is not.
Unlike list, vector, and BinaryTree, the Binary Search Tree (BST) data must have the comparison operators defined, operato<, etc.
Also findMax() and findMin(), then make sense as methods for the BST class.
A findMax() method could be written in a different class which uses a list or a vector, but the data in these would have to actually be comparable.
It is often convenient to write the operations on trees as recursive methods. This is because the tree is itself defined recursively.
These recursive methods generaly need to have a Node as a parameter!
Consequently, these methods can't be public.
So the pattern that arises is to have one public method that doesn't require a Node parameter and to have a private recursive method that is called to do all the work.
For example, here is the pair of find methods somewhat different from the BST class from text:
int find(int x)
{
// Call the private recursive find
// starting at the root of the tree.
return find(int x, root);
}
private int find(int x, Node *t)
{
private int find(int x, Node *t)
{
if ( t == null ) {
return null;
}
if ( x < t->data ) {
return find(x, t->left);
}
else if ( x > t->data) ) {
return find(x, t->right);
}
else {
return t->data;
}
}
Where is the maximum data element in a BST? the minimum data element?
These methods can easily be implemented either recursively or iteratively (using a loop) to move from the root to the largest (respectively, smallest) data element in the BST.
Insertion into a BST is very much like the find method.
public void insert(int x)
That is, move through the tree as if you were searching for x. When a null pointer is reached, attach a new node containing x.
A recursive version again uses a pair of methods. The public method return type is void, but the private method returns a pointer to the root of the modified subtree into which the data was inserted:
public void insert(int x)
{
root = insert(x, root);
}
private Node *insert(int x, Node *t)
{
if ( t == null )
t = new Node(x);
else if ( x.compareTo(t.data) < 0 ) {
t.left = insert(x, t.left);
}
else if ( x.compareTo(t.data) > 0 ) {
t.right = insert(x, t.right);
}
else {
// x is already in the tree;
// do nothing assuming duplicates are not allowed.
}
return t;
}
Here is an iterative version of the private insert method:
private Node *insert(int x, Node *t)
{
if ( t == null )
t = new Node(x);
else {
Node *p = t;
Node *q = null;
boolean found = false;
while(!found)
{
q = p;
if (x.compareTo(p.data) < 0 ) {
if ( p.left == null ) {
p.left = new Node(x);
found = true;
}
else
p = p.left;
}
else if ( x.compareTo(p.data) > 0 ) {
if ( p.right == null ) {
p.right = new Node(x);
found = true;
}
else
p = p.right;
}
else // A duplicate; not inserting duplicates
found = true;
}
}
return t;
}
As the code above reveals, insertion into a BST always occurs at a previously null link.
Deletion from a BST is more complicated. For examle, what should happen if the data at the root is deleted?
Deletion is handled by considering three essential cases:
1. The BST is empty. - Easy. Do nothing. 2. The data in Node *t to be deleted has only one child. - Make the parent of t point to t's only child. 3. The data in Node *t to be deleted has two children. - Find t's successor s (use findMin on t.right). - Copy data from s to t. - Delete s (using 2 since s will have at most one child).
If NT is the number of nodes in a binary tree T of height h, then Ph: NT <= 2h+1 - 1 This can be proved by induction on the height of the Tree. That is, prove that Ph is true for all h >= -1 Outline: a) Base cases: P-1 and P0 are easily seen to be true. b) Let S be the set of h >= 0 such that Ph is false! If we assume S is non-empty, we will show this leads to a contradiction. If S is non-empty, it contains a smallest integer, h0. By a), h0 must be at least 1. So h0 - 1 is >= 0 and Ph must be true for any h >= 0 and < h0. Now we will show Ph0 must be true, which will contradict the definition of h0. Let T be a binary tree of height h0. T has a left subtree L and right subtree R. The heights of both L and R are each < h0. #nodes(T) = #nodes(L) + #nodes(R) + 1 <= 2h0 - 1 + 2h0 - 1 + 1 = 2*2h0 - 1 = 2h0+1 - 1 But this is shows Ph0 is true, a contradition. So S must be empty; that is, Ph is true for all h >= 0.
The answer is the smallest h such that
N <= 2h+1 - 1
Solve for h:
N+1 <= 2h+1
Take logs of both sides:
log(N+1) <= h+1
or
log(N+1) - 1 <= h.
So the smallest height of a binary tree containing N nodes is
log(N+1) - 1 (rounded up)
N smallest h = log(N+1) - 1 (rounded up)
- --------------------------------------
1 round(log(1+1)) - 1 = 1 - 1 = 0
2 round(log(2+1)) - 1 = round(1.xx) - 1 = 2 - 1 = 1
3 round(log(3+1)) - 1 = round(2) - 1 = 2 - 1 = 1
4 round(log(4+1)) - 1 = round(2.xx) - 1 = 3 - 1 = 2
...
1023 round(log(1023 + 1)) - 1 = 10 - 1 = 9
1024 round(log(1024 + 1)) - 1 = round(10.xx) - 1 = 11 - 1 = 10
1. The height of a binary search tree gives the number of comparisons required to find an element in the tree in the worst case. 2. If a binary search tree has the smallest height for N nodes, the find operations is O(logN). 3. A "balanced" binary search tree keeps the height close enough to the smallest height so that the find operations is still O(logN). (But what does it mean to be balance if say, there are 5 nodes in the tree?)
If every non-leaf node in a binary tree has two children and all leaf nodes are at the same depth, the tree is definitely "balanced". However, this is too restrictive, since then the number of nodes, N, would have to be exactly:
2h -1 E.g. the size of such a tree would have to be one of 1, 3, 7, 15, 31, 63, 127, 255, ...
The catch is that BST's are not necessarily balanced or even close enough to guarantee O(log(N)) running time for find().
What binary tree do we get when the values 1, 2, 3, 4, 5 are inserted in that order into an initially empty BST?
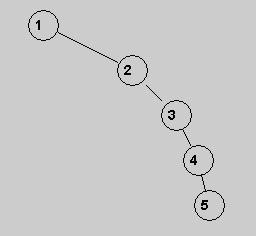
So, the worst case for find() for a BST that is not balanced is O(N).
Some restriction must be placed on a BST and its methods to ensure that it stays balanced enough to provide O(log(N)) time for find, findMax, findMin and insert.
Several different conditions have been defined, resulting in slightly different specialized BSTs.
Code is given in the book for AVL trees. There are four cases to consider when inserting into an AVL tree. However, two of them are "mirror" images of the other two.
Once this class is completed, we have a class that guarantees O(log(N)) insertion and find, including findMin and findMax.